IBMは6月11日、「IBM watsonx.data intelligence」の提供を開始すると発表した。
watsonx.data intelligenceは、AIを活用してハイブリッド・エコシステム全体のデータ配信を簡素化することで、組織がデータをキュレーション、管理、活用する方法を大きく改善する。ガバナンス、品質、データリネージ、共有を一元化することで、組織が有意義なデータを発見し、信頼し、アクセスできるようにし、データの利用者に信頼性の高いデータプロダクトを提供する。
一般提供を開始したのは、watsonx.data intelligence v2.2 である。AIを活用したインテリジェント・サーチ、データ品質ルールの作成、非構造化データガバナンスとデータリネージ、データ・プロダクトの共有などの分野で、新しい機能が搭載されている。
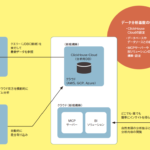
watsonx.data intelligenceには、主に以下の機能がサポートされている。
データガバナンスとカタログ
ユーザーは、SlateとGraniteの基盤モデルによる自動化されたメタデータエンリッチメントを通じて、データガバナンスを合理化する。これらのモデルはデータを分析し、拡張された列名、説明、ビジネス用語の割り当てによってビジネスコンテキストを充実させる。
列のプロパティをテーブル全体のコンテキストで調べることで、新しい機械学習技術がデータをより正確に分類する。この強化されたメタデータ・コンテキストは、データが変換され、消費される際に一緒に移動し、ツールやユースケースを超えた統一的な理解をユーザーにもたらす。IBMはv2.2で、より小さなモデルを利用することで、CPUベースの生成AI推論のサポートを追加している。
IBMはまた、データガバナンスを開始するユーザーに向けて、データソースを調査してビジネス用語集を自動的に構築する生成AIを搭載した一連の機能を導入する。堅牢な用語集は、データ・リテラシーを向上させ、データ資産の活用を促進するために重要である。
このような用語集をゼロから構築するのは煩雑で、多大の時間を要する。この新しい用語集生成機能を使用すると、同じ基盤モデルを使って用語の語彙と他の用語との関係を作成し、データガバナンスプログラムの重要な要素を迅速に開発できる。
大規模なカタログの中から適切な資産や用語を見つける作業は、困難を伴う。新しい生成AIを搭載したインテリジェント・サーチでは、言語モデルによってクエリーが拡張され、暗黙的・明示的な同義語が含まれるため、データ利用者やその他のユーザーは、より迅速に正しい結果を見つけることができる。
データ保護機能は、watsonx.dataのような製品と組み合わせることで、より強固なデータ保護対策に貢献し、リスクをコントロールし、プライバシー規制へのコンプライアンスをサポートする。
watsonx.data intelligence v2.2 は、データガバナンスを改善するために、非構造化ドキュメントセットの自動化されたメタデータエンリッチメントとカタログ化を提供し、企業が大きな価値のあるAIユースケースを生み出せるようにしている。
watsonx.data intelligence は、ドキュメント・コンテンツの機械的な理解をサポートするためにエンティティとその値を抽出し、モデル開発における再利用と共有に向けて、ビジネス用語やデータ・クラス、分類機能などを用いて、ドキュメントセットとエンティティを充実させている。
v2.2では、.pdf、.ppt、.pptx、.doc、.docxなどのファイルタイプから、埋め込み画像を含む非構造化ドキュメントを処理し、FileNet、Box、SharePoint、OneDriveなどの一般的なコンテンツ管理データソースと連携できる。
データの品質
データに対する信頼性の欠如は、依然として企業リーダーにとっての最大の懸念事項である。しかしデータ品質プログラムの開発は多くの場合、SQLの専門家の領域となる。
watsonx.data.intelligenceはこうした専門家に代わり、データの信頼性、一貫性、完全性を確保し、プロアクティブなモニタリングとサービスレベルアグリーメント(SLA)により、組織のデータ品質を継続的に可視化する。
watsonx.data intelligence v2.2 は、以下の特徴を備えている。
(1)自動化に関する多様な機能を提供し、データ品質ルールの作成に必要な手作業を削減する。
(2)割り当てられたビジネス用語に基づくデータ品質ルールの関連付けが自動化され、データ品質プログラムの展開速度を向上させる。
(3)標準偏差とZスコアに基づく新しい履歴安定性チェック機能を提供する。
データリネージ
watsonx.data intelligenceには、データリネージ機能が組み込まれており、ソースから利用までのデータの流れを継続的かつ自動的に可視化できる。
この可視性はデータの信頼性を高め、変更によるダウンストリームへの影響を最小化し、ガバナンスとコンプライアンスをサポートするために不可欠となる。手作業によるリネージの文書化とは異なり、watsonx.data intelligence はソースシステムとパイプラインを自動的にスキャンし、正確で一貫性のあるリネージを取得する。
リネージは、データカタログおよびデータ品質機能と深く統合されている。ビジネス用語、品質スコア、SLA違反は、リネージ・グラフ上に直接オーバーレイ表示されるため、ユーザーは、「データが何であるか」「どこから来たか」だけでなく、「そのデータが何を意味するか」「どの程度信頼できるか」「機密情報が含まれているかどうか」など、完全なコンテキストを得ることができる。これにより、リネージはデータ・スチュワード、エンジニア、ビジネスアナリストのための強力な調査ツールとなる。
v2.2 では、watsonx.data integration で実行される非構造化データパイプラインにも、リネージのサポートが拡張された。この機能は、ドキュメントセットのソース、処理中に適用された演算子、派生データが書き込まれた宛先など、ドキュメントセットレベルでの実行時系譜をキャプチャする。これにより、ドキュメントそのものを調査することなく、非構造化データがどのようにAIやアナリティクス用に準備されているかを可視化できるようになる。
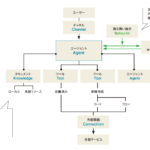
Data Product Hub
企業は、断片化されたシステム、サイロ化された所有権、不十分な発見可能性、一貫性のないガバナンスといった持続的な課題に直面している。これらの問題はイノベーションを遅らせ、コンプライアンス・リスクを増大させ、データ生産者と利用者の間に摩擦を生み出す。
Data Product Hubは、データセット、メタデータ、セマンティクス、パイプライン、ダッシュボード、AIモデルの自己完結型パッケージなど、データプロダクトを作成、管理、提供するためのツールを提供する。各製品はビジネスユースケースに関連付けられ、その形式、品質、用途を定義するデータ契約によって管理される。
ソフトウェアと同様に、データプロダクトも設計、テスト、反復のライフサイクルを経て、ユーザビリティ、価値、そしてアジャイルと、DataOpsによる継続的な改善に重点を置いている。
watsonx.data integrationの最新リリースは、データプロダクトのライフサイクルを各段階で強化する。データ利用側は、ドメイン所有者から直接プロダクトをリクエストできる。データ生産側は、データをIBMレイクハウスに取り込み、変換し、メタデータは一貫性と発見可能性のためにIBMカタログ全体で自動的に同期される。
また、IBMの新しい組み込みリネージは、ソースから利用までのデータを追跡し、セマンティック検索とビジネス用語フィルターにより、「発見」する力を向上させる。
v2.2のモニタリング・ダッシュボードにより、ユーザーは採用、使用、製品の健全性に関する洞察を引き出せる。さらにバージョン管理が強化され、ドラフト、変更追跡、リタイアメントがサポートされる。
これらの機能により、信頼性が高く、発見しやすく、ビジネスに適したデータ製品を容易に構築できるようになり、イノベーションを加速し、確信に満ちたデータ主導の意思決定を可能にする。
watsonx.data integrationの出荷開始は6月11日(米国時間)から。リソースユニット消費価格に基づいて販売され、ユーザーはプログラムで使用した分だけを支払うことが可能である。
[i Magazine・IS magazine]